绥芬 攻略教程 2024-01-29 00:38:04 0
绥芬 攻略教程 2024-01-29 00:38:04 0 伪随机,在计算机、通信系统中采用的随机,即这个码有多长都不会出现循环的现象。在计算机、通信系统中采用的随机数、随机码均为伪随机数、伪随机码,其生成方法有直接法、逆转法、接受拒绝法等。
伪随机码在码长达到一定程度时会从其第一位开始循环,由于出现的循环长度相当大,例如CDMA采用42的伪随机码,重复的可能性为4、4万亿分之一,所以可以当成随机码使用。

真正意义上的随机数(或者随机事件)在某次产生过程中是按照实验过程中表现的分布概率随机产生的,其结果是不可预测的,是不可见的。而计算机中的随机函数是按照一定算法模拟产生的,其结果是确定的,是可见的。我们可以这样认为这个可预见的结果其出现的概率是100%。所以用计算机随机函数所产生的“随机数”并不随机,是伪随机数。
伪随机,顾名思义,是一种表现为随机的数据序列,但实际上是通过一定的算法计算而得到的,其结果可以通过算法来重复生成相同的序列。
伪随机通常使用计算机程序生成,有很多常用的伪随机数生成算法,如线性同余发生器等。
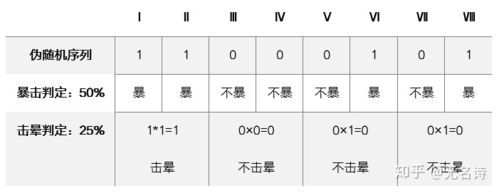
伪随机是指在有限的种子数生成的数列中,看起来呈现随机的特点,但实际上是在固定算法的控制下生成的,因此并不是真正的随机序列。
伪随机数的生成算法通常包括线性同余、梅森旋转、拉格朗日插值和迪利克雷分布等。
虽然伪随机数并不是完全随机的,但在某些情况下还是可以被广泛应用,比如在密码学中用于加密操作和在计算机图形学中生成随机图像等。
伪随机是一种非真正随机的算法,其结果具有某些随机性质,但实际上是通过确定性的计算方法生成的。
比如,在计算机程序中使用的随机数生成器常常使用伪随机数算法,这些算法基于某个初始值通过复杂的计算方法生成数列,这些数列看起来像是随机的,但实际上却是可以预测的。
伪随机相对于真随机而言更容易实现,同时也可以满足很多实际应用的需求,比如密码学、模拟实验等。
但是,在一些对随机性要求非常高的领域,如保密通信、密码破解等,伪随机的不可预测性就可能存在一定的风险。
因此,在这些领域需要使用真正的随机化方法来保证安全性。
到此,以上就是小编对于dnf是真随机还是伪随机的问题就介绍到这了,希望介绍的3点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。